
Language models like GPT-4 and Claude are powerful and useful, but the data on which they are trained is a closely guarded secret. The Allen Institute for AI (AI2) aims to reverse this trend with a new, huge text dataset that’s free to use and open to inspection.
Dolma, as the dataset is called, is intended to be the basis for the research group’s planned open language model, or OLMo (Dolma is short for “Data to feed OLMo’s Appetite). As the model is intended to be free to use and modify by the AI research community, so too (argue AI2 researchers) should be the dataset they use to create it.
This is the first “data artifact” AI2 is making available pertaining to OLMo, and in a blog post, the organization’s Luca Soldaini explains the choice of sources and rationale behind various processes the team used to render it palatable for AI consumption. (“A more comprehensive paper is in the works,” they note at the outset.)
Although companies like OpenAI and Meta publish some of the vital statistics of the datasets they use to build their language models, a lot of that information is treated as proprietary. Apart from the known consequence of discouraging scrutiny and improvement at large, there is speculation that perhaps this closed approach is due to the data not being ethically or legally obtained: for instance, that pirated copies of many authors’ books are ingested.
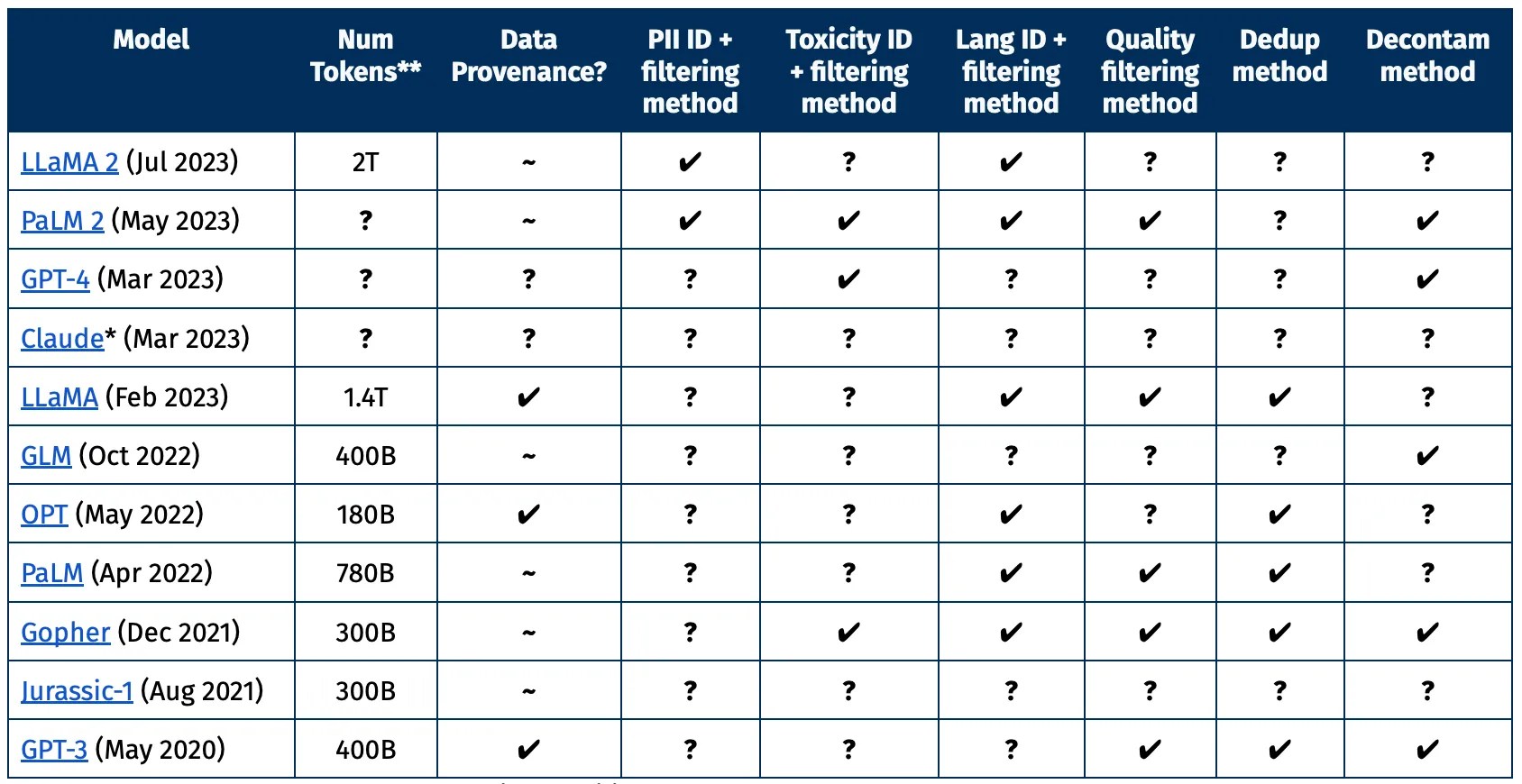
You can see in this chart created by AI2 that the largest and most recent models only provide some of the information that a researcher would likely want to know about a given dataset. What information was removed, and why? What was considered high versus low quality text? Were personal details appropriately excised?

Chart showing different datasets’ openness or lack thereof. Image Credits: AI2
Of course it is these companies’ prerogative, in the context of a fiercely competitive AI landscape, to guard the secrets of their models’ training processes. But for researchers outside the companies, it makes those datasets and models more opaque and difficult to study or replicate.
AI2’s Dolma is intended to be the opposite of these, with all its sources and processes — say, how and why it was trimmed to original English language texts — publicly documented.
It’s not the first to try the open dataset thing, but it is the largest by far (3 billion tokens, an AI-native measure of content volume) and, they claim, the most straightforward in terms of use and permissions. It uses the “ImpACT license for medium-risk artifacts,” which you can see the details about here. But essentially it requires prospective users of Dolma to:
- Provide contact information and intended use cases
- Disclose any Dolma-derivative creations
- Distribute those derivatives under the same license
- Agree not to apply Dolma to various prohibited areas, such as surveillance or disinformation
For those who worry that despite AI2’s best efforts, some personal data of theirs may have made it into the database, there’s a removal request form available here. It’s for specific cases, not just a general “don’t use me” thing.
If that all sounds good to you, access to Dolma is available via Hugging Face.
Source: techcrunch.com